Multi-Master-Ready - An Origin Story
I'm a Product Manager. Not a developer. I want to be upfront about that because everything that follows only makes sense if you understand that I have no business writing software - and I did it anyway.
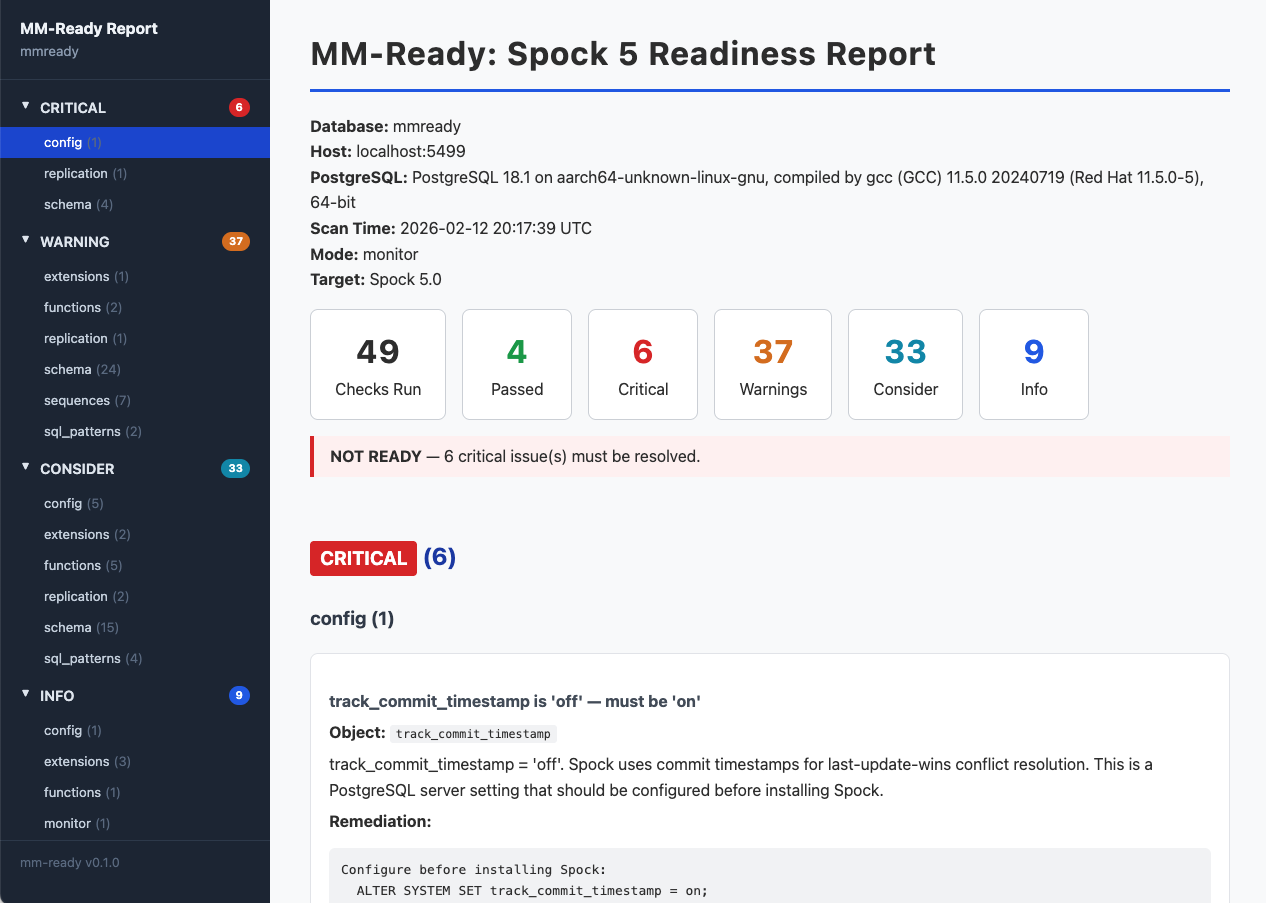
I built MM-Ready, an open-source CLI tool that scans a PostgreSQL database and tells you exactly what needs to change before you can run multi-master replication with pgEdge Spock. It checks 56 things across your schema, replication config, extensions, sequences, triggers, and SQL patterns. It gives you a severity-graded report - CRITICAL, WARNING, CONSIDER, INFO - with specific remediation steps for each finding. It runs against a live database, a schema dump file, or an existing Spock installation.
I built the first version in about four hours using Claude Code while operating in a zombie-like half-asleep state. Not so much vibe-coding as trance-coding.
The Priority that's never priority enough
Every customer evaluating the move to multi-master replication has the same question: "What, if anything, do I need to change in my database before I can turn this on?"
The answer could be "nothing", or it could potentially touch dozens of things. Tables without primary keys are insert-only replication - with logical replication, UPDATE and DELETE require a unique row identifier. Foreign keys with CASCADE actions can fire on the origin and create conflicts because foreign keys aren't validated at the subscriber. Certain sequence types don't replicate well. Some extensions aren't compatible. Deferrable constraints get silently skipped for conflict resolution. REPLICA IDENTITY FULL doesn't guarantee uniqueness for logical replication conflict resolution. So on and so forth. These things aren't bugs or issues - they're a natural consequence of a shift in operational mindset. It's akin to moving from a one-steering-wheel driving experience, and getting in a skid-steer with its highly maneuverable double-joystick.
Our Customer Success team was having to do this analysis mostly by hand. They had scripts they'd written, tribal knowledge passed between team members, and a process that worked but didn't scale. Our Slack was littered with such comments as "Wouldn't it be nice if we had a tool that checked everything?" I'd wanted to build a tool to automate this for months. It was on the roadmap. But engineering was deep in development, and this kept sliding - the thing that would make sales smoother losing to the thing that makes the product work. Classic problem. Has happened at every single place I have worked.
3 AM on remote calls, I regret quitting caffeine.
Spockfest is pgEdge's annual planning and hack week. This year it was in Istanbul. I decided to join remotely - a decision that turned out to be accidentally brilliant when a snowstorm grounded every flight that day anyway. What I forgot about was the time difference. Eight hours ahead.
So there I was, alarm going off at 1 AM, stumbling to my desk to join the calls for eight hours before my actual day had even started. For a week. I was living on one- and two-hour catnaps, no caffeine (I quit that 20 years ago), and trying to maintain the appearance of a functioning human being.
The team would break for lunch. Stretch their legs. Clear their heads. Normal stuff. I'm stuck at the keyboard. Can't go back to sleep - they'll be back in 45 minutes. Can't really start anything meaningful. Just sitting there in the dark, lit only by the glow of Google Meet, trying not to let my forehead hit the desk. So I decided to see if I could make a readiness checker with Claude Code.
Light Speed is too slow, We're going to Ludicrous Speed!
I knew the problem domain. I'd been editing the Spock documentation, talking to CS, fielding customer questions about replication readiness for months. I'd read the Spock source code - the actual C, not just the docs, because I wanted to be SURE. And to be clear, no, I can't write C code, but I can follow logic. I knew what get_replication_identity() does when you set REPLICA IDENTITY FULL without a primary key. I knew that delta-apply columns need NOT NULL constraints. I knew trigger firing behavior under session_replication_role ='replica'.
I knew what to check. I'm just 20 years removed from writing real code efficiently, effectively, coherently or with any sense of speed or developer decorum.
So I grabbed every source of knowledge I could. The Spock source code. Our documentation. The Customer Success knowledge base from JIRA. Every note I'd ever taken on things to watch out for when converting from single-primary to multi-master. I threw it all at Claude to churn through and plan out.
Then I started describing the tool. A Python CLI. A registry pattern where checks auto-discover themselves - drop a new file in the right directory and it just works. A base class with a run() method that returns findings. Severity levels as dataclasses. System catalog queries using pg_catalog, not information_schema. HTML output because I wanted something I could actually read without squinting at JSON.
The iteration speed was incredible. Describe how I wanted it to work, enjoy some silly Claude thinking messages, see it work, describe the next one. A few minutes per feature or fix. Fifty-six checks in a few hours. The hard part wasn't the code. It was knowing what to check and why - the domain knowledge accumulated for two years. By the time the team came back from lunch, I had a functioning scanner. Thanks to Claude, it had unit tests, CI tests, and documentation.
 How Fast Can This Thing Pivot?
How Fast Can This Thing Pivot?
I was all excited to show what I had to Customer Success. It didn't go quite as awesome as I'd hoped. "This is great," they said. "But we don't connect to customer databases. They send us a pg_dump --schema-only file and we analyze that."
I'd built the right tool for the wrong workflow. The entire scanner assumed live database access - querying system catalogs, checking GUC settings, inspecting pg_stat_statements. None of that works against a SQL dump file.
This is where I have to be honest about what happened, because it's embarrassing and instructive in equal measure. I fell into two classic product management traps. Traps I teach other people to avoid. Traps I have given actual presentations about.
 Trap one: "I already know the problem." I'd sat in enough CS conversations, read enough JIRA tickets, heard enough customer calls to feel confident I understood the workflow. I didn't verify. A quick Slack message - "hey, when a customer asks about Spock readiness, walk me through exactly what you do step by step" - would have saved me building the wrong thing first.
Trap one: "I already know the problem." I'd sat in enough CS conversations, read enough JIRA tickets, heard enough customer calls to feel confident I understood the workflow. I didn't verify. A quick Slack message - "hey, when a customer asks about Spock readiness, walk me through exactly what you do step by step" - would have saved me building the wrong thing first.
Trap two: scope creep dressed up as vision. I didn't just build a schema checker. I built a live database scanner, an audit mode for existing Spock installations, a monitoring mode for long-running observation, configurable check filtering, three output formats. All before validating that CS even needed any of it. Classic "while I'm in here I might as well..." thinking - except "in here" was 3 AM and I was running on fumes and hubris.
I do think the extra modes have value. A customer scanning their own live database before a migration conversation is a real use case. Auditing a running Spock deployment for things that slipped through is a real use case. But I built four tools when I could have built one, validated it, and then expanded.
Anyway. I went back and built analyze mode - a schema parser that extracts tables, constraints, indexes, and sequences from a dump file and runs the 19 checks that work from schema structure alone. The other 37 get marked as skipped with a note saying "requires live database connection." That's the mode CS actually uses.
Apart from that, Mrs. Lincoln, How was the Play?
I want to give some specifics here, because the "PM builds a tool with AI" headline writes itself, and the reality is more nuanced than that.
What I brought: domain knowledge. Eighteen months of Spock internals, customer conversations, and schema analysis experience. I could describe exactly what each check should look for, why it matters, and what the remediation should say. That part was irreplaceable. Of course, I also brought my umpteen years of product management experience - being able to describe the requirements and the reasons for them.
What Claude Code brought: the ability to turn "I need a check that finds tables without primary keys" into working, tested Python. I described the architecture. Claude wrote it.
Along the way I picked up new tools. I saw another pgEdge project using CodeRabbit for automated code review and basically ripped off their setup - their claude.md, their sub-agents, the lot. Then I learned to customize. I guess that's how everyone actually learns this stuff. You see someone doing it, you copy it, you make it yours.
If I had to pick out the big lessons I learned:
1) Setting up the CLAUDE.md file, and the .claude folder for sub-agents makes a WORLD of difference. I have the honour of working with the inestimable Dave Page, and it's his setup I ripped off. I downloaded his project next to mine, and told Claude to go examine his project for inspiration, bring over everything relevant to my project, and customize appropriately. It ended up writing an additional Spock Expert along the way.
2) Using the /plugin command and finding useful tools. One tool especially I found to be particularly amazing: https://github.com/obra/superpowers - the brainstorming, design and planning tools are amazing. Especially brainstorming. I wish I'd known about this one before I began.
3) Automated code review. I fell in love with CodeRabbit (especially its poems). My absolute favourite thing is that, apart from being free for open source projects, is that it provides a single "paste this into your AI to fix the things I found" prompt.
There were many other lessons, but they can wait for another time.
 What would I warn people about? Vibe-coding gives you speed but not understanding. You end up owning code you can't fully explain. When something breaks, you're back to describing the problem and hoping the AI can fix what the AI wrote. The test coverage exists because Claude wrote the tests too - which means the blind spots are probably shared. That thought keeps me up at night. Well … more than I was already up at night. One more thing I did bring to the table was the oversight. I watched what it was doing, like a hawk. I would frequently interrupt it, to ask it to explain what it was doing and WHY it was doing it like that. Many times I was then able to ask "why aren't you doing it this way instead?" or "wouldn't that cause this other problem?" and force it to rethink or justify its answer. Maybe that could be summarized as Wisdom or Experience - Maybe you know the saying, "Knowledge is knowing a tomato is a fruit. Wisdom is not putting it in a fruit salad".
What would I warn people about? Vibe-coding gives you speed but not understanding. You end up owning code you can't fully explain. When something breaks, you're back to describing the problem and hoping the AI can fix what the AI wrote. The test coverage exists because Claude wrote the tests too - which means the blind spots are probably shared. That thought keeps me up at night. Well … more than I was already up at night. One more thing I did bring to the table was the oversight. I watched what it was doing, like a hawk. I would frequently interrupt it, to ask it to explain what it was doing and WHY it was doing it like that. Many times I was then able to ask "why aren't you doing it this way instead?" or "wouldn't that cause this other problem?" and force it to rethink or justify its answer. Maybe that could be summarized as Wisdom or Experience - Maybe you know the saying, "Knowledge is knowing a tomato is a fruit. Wisdom is not putting it in a fruit salad".
 Oh, and the product engineers prefer Go. So I asked Claude to convert the entire project to Go. New repo. Full port. Took about an hour. I called it "MM-Ready-Go." The dad in me thought that was very funny. I had nobody to share it with at 4 AM.
Oh, and the product engineers prefer Go. So I asked Claude to convert the entire project to Go. New repo. Full port. Took about an hour. I called it "MM-Ready-Go." The dad in me thought that was very funny. I had nobody to share it with at 4 AM.
What MM-Ready Actually Does
Four modes, one goal: tell you if your PostgreSQL database is ready for multi-master replication.
Scan - Connect to a live PostgreSQL database and run all 56 checks against the system catalogs. You get an HTML report (or Markdown, or JSON) with severity-graded findings and specific remediation steps. This is for teams who want to self-assess before talking to us.
Analyze - Feed it a pg_dump --schema-only file. No database connection needed. Runs the 19 checks that work from schema structure alone. This is what our Customer Success team actually uses when a prospect sends over their schema for evaluation.
Audit - Point it at a database that already has Spock installed and running. Checks subscription health, replication set configuration, and things that might have slipped through initial setup. For existing pgEdge customers who want a health check.
Monitor - Long-running observation mode. Takes snapshots of pg_stat data and parses logs over time. For when you want to watch behavior, not just check structure.
What does it check? Primary keys. Foreign key cascade actions. Sequence types and ownership. Trigger firing behavior under replication. Unsupported extensions. Encoding mismatches. Deferrable constraints. REPLICA IDENTITY settings. WAL configuration. Advisory lock usage. TRUNCATE patterns in pg_stat_statements. And about 40 more things I won't list here because you get the point.
The checks are pluggable. Drop a new Python file in the right subdirectory, subclass BaseCheck, implement run(), and it auto-discovers. No registration needed, no rebuild. CS can add their own checks when they find new things to watch for. That was deliberate from day one - I wanted this to grow without me being the bottleneck.
 Where It Stands - Honestly
Where It Stands - Honestly
MM-Ready is on my personal GitHub repo. Not the pgEdge organization. I'm too nervous to find out everything I'd need to fix to get it "up to snuff" for the company repository. It works. CS is using the analyze mode. But it was built by a sleep-deprived PM with an AI copilot during a week where I was averaging three hours of sleep a night, and I am under no illusions about what that means for code quality.
I'm not selling you on this tool. I'm telling you it exists, it solves a real problem, and I'm excited - and terrified - to get feedback on it.
If This Is Useful to You
If you're thinking about multi-master PostgreSQL replication - or you're already evaluating pgEdge Spock - grab the tool and try it:
#Clone and install
git clone https://github.com/AntTheLimey/mm-ready.git
cd mm-ready
pip install -e .
# Analyze a schema dump (no database connection needed)
mm-ready analyze --file your_schema.sql --format html --output report.html
# Or scan a live database
mm-ready scan --host localhost --port 5432 --dbname mydb \
--user postgres --format html --output report.htmlThe GitHub repo has the full documentation. File issues. Tell me what's broken. Tell me what's missing. I can actually fix things now - I have an AI that doesn't need sleep even if I do.
If you want to talk about multi-master replication properly - MM-Ready tells you what needs to change. pgEdge is the team that actually makes the replication work. Multi-master across regions, automatic conflict resolution, standard PostgreSQL. No application changes required. If the report surfaces things you want help with, that's what we're here for.
If you're a PM who's been staring at a tool you wish existed - I'm not going to tell you to go vibe-code it at 3 AM. That was dumb. But I will tell you this: the gap between "I know exactly what this should do" and "I can build it" is smaller than it used to be. Domain knowledge matters more than it ever has. The question isn't whether you can build it. It's whether you should build it before talking to the people who'll actually use it.
I should have sent that Slack message first. Do better than I did.
Ant (Antony Pegg) is Director of Product at pgEdge, where he works on distributed PostgreSQL and tries very hard not to build things at 3 AM anymore. MM-Ready is available on GitHub. MM-Ready-Go exists too, because sometimes the joke is the feature.

